Modelowanie zagrożeń (ang. threat modeling) to ustrukturyzowane zadawanie jednego pytania: „co może pójść źle?” idealnie zanim powstanie pierwsza linijka kodu czy zanim postawisz serwer. Brzmi prosto i dobrze, bo takie jest. To nie jest żaden audyt dla wybranych ani magiczne narzędzie, które kupujesz i włączasz. To rozmowa: siadasz z zespołem, patrzysz na to, co masz zamiar zbudować, i zawczasu wynajdujesz sposoby, w jakie ktoś mógłby tego nadużyć.
Ten przewodnik jest dla zespołów wytwórczych: tech leadów, architektów, programistów i Security Championów (wszystkich, którzy odpowiadają za to, żeby oprogramowanie i infrastruktura były bezpieczne, a niekoniecznie chcą tytułować się „bezpiecznikami”). To mapa całego tematu. Po kolei odpowiemy na pytania: czym to właściwie jest? po co to robić? kiedy w cyklu? na jakich poziomach? jak wygląda sesja? jakie metody możemy wykorzystać? jak rysować architekturę (DFD)? jakie narzędzia wybrać? jak potem priorytetyzować? co zrobić z wynikami? jak zadbać o prywatność? czy muszę robić coś pod regulacje (compliance)? jakie błędy najłatwiej popełnić? i jak w ogóle wdrożyć cały ten proces? W każdym wątku pokażemy też, jak kopać głębiej, bo cały temat jest szeroki i głęboki, a szczegóły docelowo mieszkają w osobnych artykułach (część już w tej fali, część później).
Zapraszamy do lektury!
Czym jest modelowanie zagrożeń?
Zacznijmy od definicji, bo dobra definicja od razu ustawia całą resztę. Najlepszą znajdziemy w Threat Modeling Manifesto: modelowanie zagrożeń to analiza reprezentacji systemu w celu podkreślenia problemów związanych z bezpieczeństwem lub prywatnością — i wszystko w tej definicji jest ważne.
Rozłóżmy to na części pierwsze, bo każde słowo robi tu swoją robotę. Analiza: praca myślowa, nie skan. Reprezentacji systemu: nie patrzymy na sam system, tylko na jego model, bo „mapa to nie teren”. Problemów z bezpieczeństwem lub prywatnością: to dwa różne wymiary, do tego jeszcze wrócimy. Mówiąc krótko: modelowanie zagrożeń to ustrukturyzowany proces identyfikacji i ograniczania zagrożeń dla systemu na etapie projektowania, czyli idealnie zanim zdążą zamienić się w podatności w kodzie działającym na produkcji.
Sercem każdej sesji są trzy pytania, które spopularyzował Adam Shostack:
- Co budujemy? Odwzoruj system.
- Co może pójść źle? Znajdź zagrożenia.
- Co z tym zrobimy? Zaplanuj reakcję.
Jest jeszcze czwarte, bonusowe: „Czy zrobiliśmy wystarczająco dobrze?” To pytanie walidacyjne, zadawane post factum (domykane przeglądem i testami), nie w trakcie samej sesji. Trzy fundamentalne plus jedno bonusowe. I tyle, aż tyle.
Teraz wspomniane wcześniej dwa wymiary. Bezpieczeństwo to nie to samo co prywatność: to dwie ortogonalne osie. Bezpieczny system może w ogóle nie dbać o prywatność, a system dbający o prywatność może być dziurawy jak ser. Do problemów związanych z bezpieczeństwem używamy w BK taksonomii STRIDE, a do problemów dotykających prywatności: TRIM.
I jeszcze jedno rozróżnienie, które rynek nagminnie zlewa w jedno: proces ≠ sesja ≠ model. To trzy różne rzeczy. Proces odpowiada na pytania jak, kiedy, dla kogo i co z tego powstaje, to poziom organizacji. Sesja to jedna instancja robocza, ten jeden raz, kiedy siadamy i przepuszczamy system przez STRIDE. Model zagrożeń to artefakt, który (czasem) z sesji wychodzi, bywa bardzo różny, a niekiedy formalnego modelu w ogóle nie ma. Czemu to ważne? Ponieważ tu leży luka rynkowa: zdecydowana większość tego, co można znaleźć o modelowaniu zagrożeń (artykuły, szkolenia, prezentacje) skupia się właśnie na samej sesji, jakby reszta nie istniała. My pokrywamy cały proces.
Stąd ostatnia myśl tej sekcji: pojedyncza sesja daje częściowy widok. I to jest OK. Modelowanie zagrożeń to powtarzalna praktyka w duchu „little and often”, a nie jednorazowy rytuał. Mówiąc krótko: maraton, nie sprint.
Po co modelować zagrożenia? Argument biznesowy
Skoro to dodatkowa praca, to po co ją sobie dokładać? Już mówimy. Strategicznym celem modelowania zagrożeń, z punktu widzenia organizacji, jest obniżenie kosztu bezpieczeństwa.
Czemu to działa? Ponieważ koszt naprawy podatności rośnie z fazą. Im później wyłapiesz problem, tym drożej go usuniesz. Błąd złapany na tablicy, na etapie projektowania, kosztuje rozmowę. Ten sam błąd złapany na produkcji kosztuje incydent, hotfix, regresję i często cały przebieg jednego cyklu wytwórczego. Skala robi wrażenie: według badania IBM Integrating Software Assurance into the SDLC naprawa wady wykrytej już po wdrożeniu (na produkcji / w utrzymaniu) potrafi kosztować około 100× tego, co kosztowałaby na etapie projektowania.
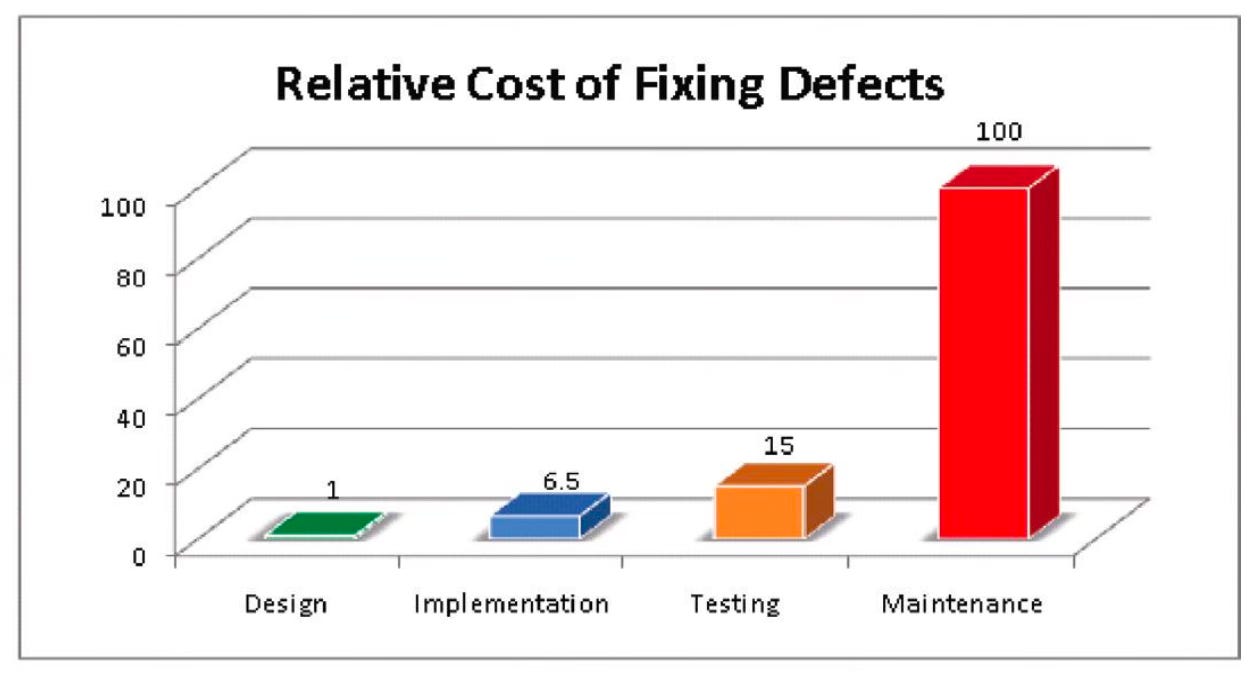
To właśnie sedno shift-left, czyli przesuwania dbania o bezpieczeństwo „w lewo”, na wcześniejsze fazy procesu wytwórczego (SDLC). I dlatego modelowanie zagrożeń jest tak wyjątkowe: to jedyna PROAKTYWNA praktyka bezpieczeństwa. Działa, zanim powstanie pierwsza linijka kodu. Lepiej i taniej unikać błędów, niż je później poprawiać.
Kiedy w cyklu wytwórczym? (security by design)
OK, to kiedy usiąść do modelowania? Najogólniej: w fazie projektowania cyklu wytwórczego (SDLC). A konkretniej: idealnie przy nowym systemie, nowym feature, zmianie architektury albo nowej integracji. To właśnie ten moment, w którym za garść decyzji projektowych można kupić sobie spokój na produkcji.
To jest dokładnie sedno security by design, czyli bezpieczeństwa wbudowanego w produkt od początku, a nie doklejonego pod koniec, gdy „trzeba jeszcze przejść audyt”.
Poziomy modelowania zagrożeń (na czym i na jakiej wysokości)
Najpierw zajmijmy się obaleniem najgroźniejszego mitu: że istnieje jeden sposób, żeby modelować zagrożenia. Otóż nie. Modelowanie wygląda inaczej na różnych poziomach.
Poziomy są cztery, zagnieżdżone: Organizacja ⊃ System ⊃ Aplikacja ⊃ Funkcjonalność. Na każdym z nich siedzi kto inny, patrzy na co innego i wychodzi mu inny artefakt. To nie jest „jeden rozmiar dla wszystkich”.
Co dokładnie się zmienia z poziomu na poziom? Przede wszystkim driver sesji, czyli to, czym napędzamy myślenie „co może pójść źle”. Na poziomie organizacji to MITRE ATT&CK; na poziomie systemu i aplikacji to STRIDE i TRIM wsparte odpowiednią biblioteką ataków (OWASP Top 10 for Kubernetes / for CI-CD dla systemu, OWASP Top 10 dla aplikacji); na poziomie funkcjonalności: lekki STRIDE i TRIM plus CWE Top 25 oraz abuse stories. Biblioteka ataków to też driver, więc dobierasz ją do poziomu.
Uwaga, bo to częsta pułapka: notacja (DFD/PFD/C4/diagram architektury) i metodyka (jak Agile Threat Modeling czy RTMP) to osobne osie, one poziomów nie różnicują. Notacji można użyć na każdym poziomie. Metodyka z kolei narzuca preferowany driver (to dlatego driver jest częścią metodyki, a nie odwrotnie). I trzymamy mocno jedno rozróżnienie: DFD to nie STRIDE — DFD to reprezentacja systemu, STRIDE to driver sesji.
Zmienia się też artefakt, i to gradientem. Na poziomie organizacji powstaje formalny model (wkładka do analizy ryzyka i ciągłości działania). Na poziomie systemu też formalny (wkładka do oceny bezpieczeństwa: pentestu / oceny podatności). Na poziomie aplikacji model niekoniecznie jest formalny (czasem to po prostu zdjęcie tablicy) i wprost zasila backlog. Na poziomie funkcjonalności często nie ma formalnego modelu: wychodzą z niej kryteria akceptacji, wpisy do Definition of Done i zadania w backlogu.
Wprowadzamy poziomy nie dla porządku, tylko żeby dobrać właściwe narzędzie do właściwej roboty. Pełną macierz (kto, na co patrzy, czym modeluje, jaki artefakt, w jakim trybie i kiedy) rozkładamy w osobnym, szczegółowym artykule: poziomy modelowania zagrożeń: kto, co i czym modeluje.
Jak wygląda sesja modelowania zagrożeń?
Dobrze, a jak to wygląda w praktyce, minuta po minucie? Przepływ jednej sesji to z grubsza pięć kroków:
- Odwzoruj system — narysuj go (DFD / PFD).
- Znajdź zagrożenia: przepuść go przez STRIDE i biblioteki ataków („co może pójść źle?”).
- Spriorytetyzuj, bo nie wszystko naprawisz naraz.
- Zaplanuj reakcję: przekuj zagrożenia w konkretne wpisy do backloga.
- Domknij pętlę: retro po sesji, a później walidacja w testach.
Logistyka w jednym zdaniu: zwykle 3–6 osób, około 45–90 minut (zależnie od zakresu), zawsze w timeboxie, czasami z dogrywką. Krok po kroku, z agendą, rolami i przykładami, przechodzimy w osobnym artykule: sesja modelowania zagrożeń krok po kroku.
Metody: STRIDE i pozostałe
Od jakiej metody zacząć? Praktycznie zawsze: od STRIDE. Tylko najpierw obalmy mit, bo to klucz do całej reszty. STRIDE to nie metodyka — to taksonomia zagrożeń używana jako driver. To mnemonik (ang. Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege), który podpowiada, jakie rodziny zagrożeń przyłożyć do systemu w burzy mózgów. Innymi słowy: STRIDE nie mówi, jak przeprowadzać sesję, mówi, o co pytać podczas analizy.
A to, że kategorie STRIDE czasem się na siebie nakładają (jedno zagrożenie pasuje do dwóch liter)? To cecha, nie błąd: chodzi o to, by nic nam nie umknęło, a nie o sztywne szufladkowanie. Szczegóły, przykłady i jak go stosować zebraliśmy osobno: STRIDE jako driver sesji.
Co z prywatnością? Tu wjeżdża TRIM (od F-Secure, zbudowany na wzór STRIDE) jako dodatkowy driver.
Wspomniane biblioteki ataków to też drivery, dobierasz je do poziomu i roli (organizacja → MITRE ATT&CK; system → OWASP Top 10 for Kubernetes / for CI-CD; aplikacja → OWASP Top 10; funkcjonalność → CWE Top 25).
Jak narysować DFD (diagram przepływu danych)
Zanim cokolwiek przepuścisz przez STRIDE, musisz mieć na czym to robić, czyli reprezentację systemu. Najczęstszą notacją wykorzystywaną w modelowaniu zagrożeń jest DFD (ang. Data Flow Diagram, czyli diagram przepływu danych): pięć elementów, które wystarczają, by oddać przepływ danych przez system. DFD nieznacznie różni się od diagramu architektury, a bliższy programistom bywa PFD (ang. Process Flow Diagram).
I tu wraca rozróżnienie, którego pilnujemy w całym przewodniku: DFD to nie STRIDE. DFD to reprezentacja systemu (na czym pracujemy), STRIDE to driver sesji (czym ją napędzamy). Mapa to nie teren: sam diagram nie znajdzie zagrożeń, ale bez niego nie ma czego analizować. Jak narysować DFD krok po kroku (i kiedy sięgnąć po PFD) pokazujemy osobno: jak narysować DFD.
Narzędzia do modelowania zagrożeń
A czym to wszystko rysować? Krótki przegląd: w zupełności wystarczy tablica i aparat w telefonie. Z narzędzi cyfrowych sięgamy najczęściej po draw.io (z szablonem DFD — to nasz wybór), jest też Microsoft Threat Modeling Tool i OWASP Threat Dragon. Dla chętnych istnieje „threat modeling as code” (pytm, Threagile), a na drugim końcu drogie rozwiązania komercyjne jak IriusRisk (raczej pod duże organizacje).
Jedna rzecz jest jednak ważniejsza niż wybór narzędzia. Żadne narzędzie nie zrobi za Ciebie modelowania. Narzędzie skaluje proces, nie osąd. Bo bezpieczeństwo to proces, nie produkt.
Priorytetyzacja zagrożeń
Sesja zwykle wypluwa więcej zagrożeń, niż jesteś w stanie naprawić od razu. Czym więc priorytetyzować? Trzy popularne podejścia: DREAD (granularny, choć skala 1–3 bywa w boju kłopotliwa; to lekcja, którą sami wynieśliśmy z PoC), macierz 3×3 (prawdopodobieństwo × wpływ, klasyka analizy ryzyka, dobra do łączenia wyników z różnych procesów) oraz dot voting (szybkie, ale „na czuja”).
Tu jednak ważna uwaga, którą warto sobie zakodować: te metody oceniają krytyczność (ang. criticality), nie ryzyko (ang. risk). Bezpiecznicy nagminnie używają tych dwóch słów jak synonimów. Czemu to nie ryzyko? W modelowaniu „w przód” nie istnieje jeszcze podatność ani ekspozycja, mamy potencjalne zagrożenie, a nie udokumentowaną lukę. Skoro nie ma podatności, nie ma z czego policzyć ryzyka. Dlatego nadajemy zagrożeniu krytyczność/priorytet. Krytyczność jest stała i niezależna od miejsca zasobu; ryzyko zawsze zależy od kontekstu.
Co zrobić z wynikami: backlog
Masz listę zagrożeń, masz priorytety. I co dalej? Tu pada nasza ulubiona pułapka: „wrzucimy do backloga” to za mało. Czemu? Bo ogólnikowy wpis w backlogu po dwóch sprintach nikt nie wie, jak zamknąć. Zamiast tego zobowiąż się do konkretnego formatu agile. Mamy ich 5: Tech Debt, Acceptance Criteria (w schemacie GIVEN-WHEN-THEN), Definition of Done, Timeboxed Spike oraz Epic.
Dobra wiadomość: modelowanie zagrożeń nie wymaga nowego procesu. Często wpina się w to, co już macie. Każdy z tych pięciu formatów to coś, czego większość zespołów zwinnych (ang. Agile) używa w codziennej pracy. Pełne ujęcie z przykładami zapisu znajdziesz osobno: 5 formatów akcji do backloga.
Prywatność: modelowanie zagrożeń prywatności (TRIM)
Wracamy do osi prywatności, bo zasługuje na własny akapit. Skoro bezpieczeństwo ≠ prywatność, to prywatność potrzebuje własnego drivera. U nas jest nim TRIM (od F-Secure: Transfer, Retention-Removal, Inference, Minimisation), narzędzie zbudowane na wzór STRIDE, używane jako dodatkowy driver na poziomie systemu, aplikacji i funkcjonalności. Podział jest prosty: STRIDE obsługuje bezpieczeństwo, TRIM obsługuje prywatność. Dwa niezależne drivery, dwie ortogonalne osie.
TRIM naturalnie spina się z RODO (pytania o transfer danych poza UE, retencję, minimalizację). Istnieje też LINDDUN — pełniejszy, ale przez to bardziej toporny; nie jest naszym pierwszym wyborem, choć mamy z nim doświadczenie i jeśli klient tego potrzebuje, możemy je wdrożyć. My preferujemy TRIM: w zupełności wystarcza do modelowania zagrożeń prywatności w kontekście, który dotyczy nas najczęściej, czyli RODO/GDPR dla systemów wytwarzanych w Unii Europejskiej.
Modelowanie zagrożeń a regulacje: NIS2 / DORA / CRA
Czy modelowanie zagrożeń jest wymagane prawem? I tak, i nie. W tekstach regulacji nie pada wprost, ale jest silnie implikowane. NIS2 i krajowa ustawa (KSC) wymagają analizy ryzyka (Art. 21(2)(a)) oraz bezpiecznego SDLC (rozporządzenie wykonawcze CIR 2024/2690, §6.2, plus wytyczne ENISA). KSC wchodzi w życie 3 kwietnia 2026, temat robi się więc gorący. Obok stoją DORA (sektor finansowy) i CRA (produkty z elementami cyfrowymi).
A z perspektywy zakupowej? Compliance to udokumentowany wyzwalacz numer jeden decyzji o wdrożeniu. Pełne mapowanie wymogów na praktyki rozkładamy osobno: NIS2 / DORA / CRA a modelowanie zagrożeń.
Najczęstsze błędy
Czego unikać? Oto krótka lista, bezpośrednio z naszego doświadczenia:
- jednorazowy „akademicki” rytuał zamiast powtarzalnej praktyki,
- brak właściciela procesu,
- modelowanie zbyt szczegółowo albo zbyt późno,
- brak powiązania wyników z backlogiem,
- jedno narzędzie wciskane do wszystkiego, na każdym poziomie,
- STRIDE traktowany jak sztywna klasyfikacja zamiast jako driver do burzy mózgów,
- retroaktywne modelowanie robione wyłącznie „pod compliance”.
Jak wdrożyć modelowanie zagrożeń? (Security Champions)
Jak przejść od pierwszej, facylitowanej sesji do powtarzalnej praktyki, którą zespoły robią samodzielnie? Z grubsza: szkolenie → facylitowane sesje → samodzielność. Motorem są Security Championi: bezpieczników jest zawsze za mało, więc praktyka musi rozejść się po zespołach wytwórczych.
Jest jednak haczyk, którego nauczyliśmy się w boju: dział bezpieczeństwa musi posiadać i zaprojektować proces, nie wolno zrzucać całego procesu na samych Championów. To, czy wdrażać top-down czy bottom-up, zależy od wielkości organizacji.
Co robić, jak żyć?
Zbierzmy to w pięć praktycznych kroków:
- Ustal, na którym poziomie modelujesz, i dobierz driver sesji. Organizacja, system, aplikacja czy funkcjonalność: od tego zależy wszystko inne poziomy modelowania zagrożeń.
- Odwzoruj system właściwą notacją (DFD/PFD/diagram architektury; pamiętaj: notacja ≠ driver) i przejdź przez STRIDE.
- Spriorytetyzuj wg krytyczności (DREAD / macierz ryzyka) i zapisz akcje w backlogu w konkretnym formacie agile.
- Wepnij to w istniejący proces i zacznij małym, iteracyjnym krokiem: „little and often”.
- Pamiętaj, że częściowy widok jest OK. To maraton, nie sprint.
Sednem modelowania zagrożeń jest uniknięcie zagrożeń, które znajdziemy. Dobranie właściwego narzędzia do właściwego poziomu to ważna część tego procesu, nie cel sam w sobie.
Damy Ci znać, gdy opublikujemy coś nowego.
Artykuł albo odcinek podcastu. Bez spamu. W każdej chwili możesz się wypisać.
Zapisując się, akceptujesz politykę prywatności.
Referencje i wzmianki: Adam Shostack, Threat Modeling: Designing for Security; OWASP; MITRE ATT&CK; Microsoft (historia STRIDE/DREAD); IBM, „Integrating Software Assurance into the SDLC” (researchgate.net/publication/255965523); NIS2 / KSC (Dz.U. 2026 poz. 252).