Wokół modelowania zagrożeń (ang. threat modeling) narosło sporo mitów. Jeden z najbardziej szkodliwych brzmi tak: istnieje jeden sposób, żeby to robić. Bierzesz diagram przepływu danych, dorzucasz STRIDE, albo kupujesz drogie narzędzie i wdrażasz je wszędzie tak samo. Koniec, gotowe.
Brzmi wygodnie. Problem w tym, że nie działa. Bo kiedy ktoś z tym przekonaniem siada, żeby zamodelować zagrożenia dla całej organizacji za pomocą diagramu przepływu danych i STRIDE, szybko ląduje w ślepej uliczce. I słusznie się wtedy zastanawia, czy to z nim coś jest nie tak. Otóż nie: to z podejściem.
Modelowanie zagrożeń wygląda inaczej na różnych poziomach. Inaczej modeluje się ryzyko całej firmy, inaczej pojedynczy system, a jeszcze inaczej konkretną funkcjonalność, nad którą programista pracuje w sprincie. Kto inny przy tym siedzi, czym innym to robi i zupełnie inny artefakt z tego wychodzi. W tym przewodniku rozkładamy to na cztery poziomy i pokazujemy, kto, na co patrzy, czym modeluje, jaki artefakt powstaje i kiedy ma to sens.
Dlaczego „jeden rozmiar dla wszystkich” zawodzi
Zacznijmy od źródła problemu, bo on ma dwie strony.
Z jednej strony są eksperci (ludzie, którzy głośno mówią o modelowaniu zagrożeń), często sprzedający je jako jeden uniwersalny proces: jedna metoda, jedno narzędzie, jeden rozmiar dla całej organizacji. Z drugiej strony są odbiorcy, którzy biorą tę receptę i próbują wdrożyć ją u siebie jeden do jednego. I się odbijają.
Czemu? Ponieważ co innego robi dział bezpieczeństwa, modelując zagrożenia dla organizacji. Co innego robią architekci, patrząc na pojedynczy system i jego integracje. A co innego robią programiści, modelując zagrożenia dla aplikacji czy pojedynczej funkcjonalności. To są różne role, które patrzą na różne rzeczy i potrzebują różnych narzędzi: zarówno procesowych (czym napędzamy sesję, jak STRIDE czy biblioteka ataków), jak i technicznych (czym rysujemy model). Na końcu wychodzą im też różne artefakty.
Posłużymy się analogią, bo dobrze tu pasuje. Mapy mają różne skale. Mapy świata nie użyjesz, żeby trafić do konkretnego pokoju w budynku, a rzutu pojedynczego pomieszczenia nie użyjesz, żeby zaplanować podróż przez kontynent. Jedno i drugie to „mapa”, ale do innego zadania. Z modelowaniem zagrożeń jest tak samo.
I tu główna teza tego artykułu: wprowadzamy poziomy nie dla widzimisię, nie dla porządku, tylko po to, żeby dobierać właściwe narzędzie do właściwej roboty.
Cztery poziomy modelowania zagrożeń (z lotu ptaka)
Poziomy są zagnieżdżone, a więc jeden zawiera się w drugim:
Organizacja (infrastruktura) ⊃ System ⊃ Aplikacja ⊃ Funkcjonalność.
Innymi słowy: organizacja składa się z systemów, system to zestaw aplikacji, aplikacja to zestaw modułów i serwisów, a te to zbiory funkcjonalności. Im niżej schodzimy, tym węższy mamy zakres i tym bliżej jesteśmy konkretnego kodu.
Mała uwaga, jeśli kojarzysz nasze szkolenia: tam dla uproszczenia mówimy o trzech poziomach: infrastruktura, aplikacja, funkcjonalność. Tutaj rozbijamy to nieco drobniej, na cztery, ale mapowanie jest banalne: organizacja ≈ infrastruktura, system i aplikacja ≈ aplikacja, moduł i funkcjonalność ≈ funkcjonalność. To ten sam model, tylko z większym przybliżeniem.
Druga uwaga, ważniejsza: to jest gradient, nie zestaw szczelnych szufladek. Granice są płynne. Nie chodzi o to, że dana rola „nie ma prawa” pojawić się na innym poziomie, bo często może wnieść wartościową wkładkę. Chodzi o to, kto natywnie pasuje na danym poziomie, kogo realnie spotkasz na takiej sesji.
Zanim wejdziemy w szczegóły, oto cała czwórka z lotu ptaka:
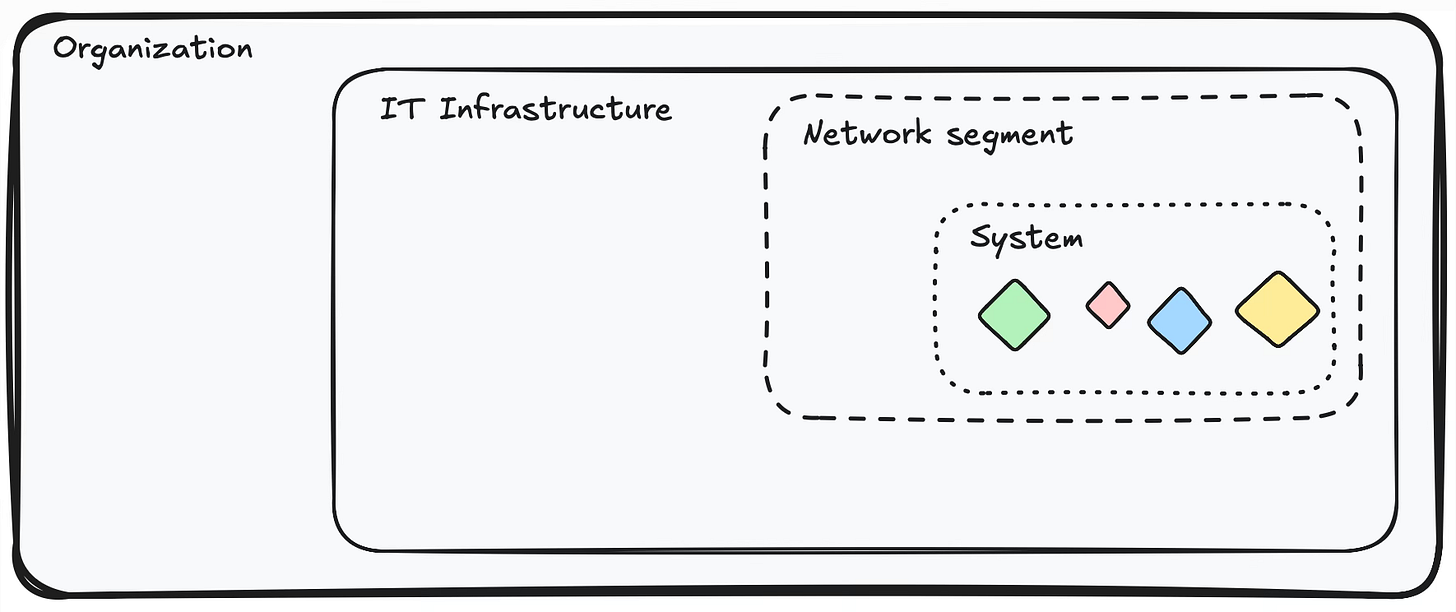
| Poziom | Kto natywnie modeluje | Na co patrzymy | Driver sesji (czym modelujemy) | Artefakt | Tryb | Kiedy |
|---|---|---|---|---|---|---|
| Organizacja (infrastruktura) | CISO (nadzór), dział bezpieczeństwa / IT / administratorzy (nie programiści) | całe portfolio systemów, przepływy między nimi, ludzie (socjotechnika), ryzyko biznesowe | MITRE ATT&CK (STRIDE słabo pasuje) | formalny model (wkładka do analizy ryzyka i ciągłości działania; ew. do ćwiczenia red teamingowego) | globalny | rzadko (np. raz/rok), zmiana krajobrazu / compliance |
| System | architekci + security / staff engineer (nie CISO) | pojedynczy system + integracje (co wchodzi, co wychodzi) | STRIDE + TRIM (prywatność) + biblioteka ataków (np. OWASP Top 10 for Kubernetes / for CI-CD) | formalny model zagrożeń (wkładka do oceny bezpieczeństwa: pentest / ocena podatności) | globalny | nowy system albo duża zmiana (migracja, integracja, chmura) |
| Aplikacja | tech lead, architekt, programiści, devops, Security Championi (nie IT / administratorzy) | komponenty i przepływy danych w aplikacji | STRIDE + TRIM (prywatność) + biblioteka ataków (OWASP Top 10) | model zagrożeń (niekoniecznie formalny — np. zdjęcie tablicy) → akcje do backloga | globalny / iteracyjny | zmiana lub nowy feature, wycinek sprintu |
| Funkcjonalność | programista / Security Champion / tester QA | pojedyncza funkcja / user story | lekki STRIDE + TRIM + biblioteka ataków (CWE Top 25) + abuse stories; checklisty | często brak formalnego → kryteria akceptacji / DoD / wpisy do backloga (abuser story / refinement / requirement) | iteracyjny | per sprint / per story (zależnie od „rozmiaru koszulki") |
- Notacja (na czym modelujemy): DFD, PFD, C4, diagram architektury — można jej użyć na każdym poziomie; wybór zależy od tego, co zna zespół. W praktyce diagram architektury i C4 bywają naturalniejsze wyżej (organizacja/system), a DFD/PFD niżej (aplikacja/funkcjonalność) jak rysować DFD.
- Metodyka (jak prowadzimy sesję/proces): np. Agile Threat Modeling, RTMP. Driver jest częścią metodyki — to metodyka narzuca preferowany driver sesji (np. Agile Threat Modeling preferuje STRIDE). Obie pasują bardziej do poziomu systemu/aplikacji/funkcjonalności niż organizacji.
- Priorytetyzacja: DREAD, matryca ryzyka, dot voting.
Driver sesji — a biblioteka ataków też jest driverem — to ta jedna oś, która realnie zmienia się z poziomu na poziom, i dlatego trafia do tabeli.
A teraz przejdźmy przez poziomy po kolei, z góry na dół.
Poziom 1: Organizacja (infrastruktura)
Najwyższy poziom. Patrzymy z lotu ptaka na całą firmę.
Kto przy tym siedzi? Nadzór sprawuje CISO, a wykonują dział bezpieczeństwa, IT i administratorzy. Po stronie bezpieczeństwa pasuje tu raczej architekt bezpieczeństwa niż szeregowy pentester. Programistów na tym poziomie zwykle nie ma i nie powinno być, bo nie o ich pracę tu chodzi.
Na co patrzymy? Na całe portfolio systemów i na przepływy między nimi. Ale nie tylko na warstwę IT: bierzemy też pod uwagę ludzi, więc ataki socjotechniczne jak najbardziej są w zakresie. Pytanie u podstaw nie brzmi „czy ten serwer jest bezpieczny”, tylko: co sprawi, że nasza firma jako biznes przestanie dostarczać wartość?
Czym modelujemy? Sesję napędza tu MITRE ATT&CK — biblioteka ataków operująca na poziomie całej organizacji. STRIDE? Można go wcisnąć, ale jest słabym wyborem na tym poziomie: zaprojektowano go do myślenia o danych i użytkownikach, nie o całej organizacji.
A na czym to opieramy? Na wysokopoziomowej reprezentacji organizacji: mapie systemów, rejestrze ryzyk, diagramie architektury enterprise z integracjami i platformami, z których korzystamy (jeśli żyjemy na Microsoft 365 czy Google Workspace, to też element tego obrazu). Sama notacja to osobna oś; wracamy do niej w ramce pod tabelą.
Tu pojawia się ważny kontekst: na poziomie organizacji modelowanie zagrożeń stoi tuż obok analizy ryzyka i jest istotnym wkładem do niej oraz do ciągłości działania (ang. business continuity). Żeby mieć sensowną strategię cyberbezpieczeństwa, trzeba najpierw wiedzieć, co nam jako organizacji zagraża. Jedno zastrzeżenie: to nie jest analiza konkurencji ani zagrożeń rynkowych. Mówimy o zagrożeniach dla bezpieczeństwa informacji, a nieco rzadziej ogólnego cyberbezpieczeństwa.
Artefakt jest tu formalny i wysokopoziomowy, a jego odbiorcami są osoby na poziomie zarządu — to oni powinni być świadomi profilu ryzyka organizacji, którą nadzorują. Taki model bywa też wkładką do analizy ryzyka i ciągłości działania, a czasem do ćwiczenia red teamingowego. Tryb to modelowanie globalne. Kiedy? Rzadko: spokojnie raz w roku, czasem nawet rzadziej, bo na tym poziomie krajobraz nie zmienia się z dnia na dzień. Wyzwalaczem jest najczęściej upływ czasu (warto usiąść i zrewidować, czy środowisko wokół nas się nie zmieniło) albo wymogi compliance, bo i regulacje takie jak NIS2, DORA czy CRA de facto wymagają, byś wiedział, co Ci zagraża.
Poziom 2: System
Schodzimy piętro niżej. System rozumiemy tu jako zestaw aplikacji wraz z ich integracjami.
Kto? Tu wchodzą architekci (solution i enterprise) oraz osoby ze świata staff engineeringu i bezpieczeństwa. CISO już raczej nie nadzoruje ani nie uczestniczy na tym poziomie; jego perspektywa jest za wysoko.
Na co patrzymy? Na pojedynczy system i jego integracje: co do niego wchodzi, co z niego wychodzi, jak rozmawia z resztą świata.
Czym modelujemy? Tu sesję napędza już STRIDE, wsparty biblioteką ataków dobraną do skali systemu: zamiast ogólnego OWASP Top 10 sięgamy po listy „systemowe”, jak OWASP Top 10 for Kubernetes czy dla CI/CD, jeśli to tam żyją nasze systemy. Jeśli patrzymy pod kątem prywatności, dokłada się TRIM.
A na czym to rysujemy? To osobna oś (patrz ramka pod tabelą). W praktyce na tym poziomie naturalnie wchodzi diagram architektury albo C4, który jest o tyle ciekawy, że pozwala spojrzeć na ten sam system z różnej wysokości; DFD też zadziała. Warunek jest jeden: notację musi znać zespół. Jeśli nikt nie zna C4, trzeba się go najpierw nauczyć albo sięgnąć po coś, co rozumieją wszyscy.
I tu dochodzimy do mechanizmu, który najlepiej pokazuje, dlaczego modelowanie zagrożeń realnie obniża koszt bezpieczeństwa. Architekci budują model na etapie projektowania, proaktywnie, zanim powstanie kod. Ale ten sam artefakt trafia później do testerów bezpieczeństwa, pentesterów i red teamu, którzy podczas testów go walidują i uzupełniają.
Świetnie ujął to Serhii Pronin (Head of Security w Booksy) w komentarzu pod jednym z naszych materiałów: przekazanie wyników modelowania zagrożeń zespołowi testów to w praktyce „requirement-driven security testing”, gdzie testerzy skupiają się na najistotniejszych zagrożeniach, zamiast działać po omacku, w trybie eksploracyjnym. A ta zwrotna pętla między modelem a testami pozwala domknąć luki, które prześlizgnęłyby się nawet przy dobrym modelowaniu.
Dorzucimy do tego jedno: modelowanie zagrożeń jako proces powinno służyć nie tylko inżynierom (żeby mogli unikać błędów), ale i testerom (żeby mogli zwalidować, czy się udało). Co więcej: testerzy przy tej walidacji wzbogacają sam model. I tak to zrobią, bo na końcu każdy pentester nieformalnie modeluje zagrożenia; szkoda tylko, że ta wiedza zwykle nigdzie nie wraca. Sformalizujmy ten obieg, a pętla zwrotna zacznie pracować na nas.
W BNP Paribas ten układ był bardzo namacalny. Jak mówił Filip Brandt, architekt bezpieczeństwa banku: „testujemy penetracyjnie bardzo dużo asetów wewnętrznie”. Przy tej skali model zagrożeń systemu naturalnie staje się punktem wyjścia dla testerów, którzy go walidują i uzupełniają.
Tryb to znów modelowanie globalne. Kiedy? Albo na starcie budowy nowego systemu (czyli w pełni proaktywnie), albo przy dużej zmianie: wymieniamy kluczowe narzędzie, migrujemy kolejkowanie na inny silnik, przenosimy się do chmury. Wtedy warto usiąść i przemodelować.
Poziom 3: Aplikacja
To poziom, który większość ludzi ma na myśli, mówiąc „modelowanie zagrożeń w procesie wytwórczym”. Wchłaniamy tu moduł, serwis, komponent czy mikroserwis: to wszystko jest po prostu aplikacją, raz większą, raz mniejszą.
Kto? Tech lead, architekt, programiści, devops, a także Security Championi, bo oni najczęściej wywodzą się z zespołów deweloperskich albo są blisko kodu. Kogo tu raczej nie ma? Administratorów i osób z IT — na tym poziomie ich udział w sesji nie ma większego sensu.
Na co patrzymy? Na aplikację, jej komponenty i przepływy danych: zarówno wewnątrz, między komponentami, jak i na to, co do aplikacji wpada i co z niej wychodzi.
Czym modelujemy? Tu wjeżdża klasyka procesu wytwórczego: sesję napędza STRIDE, a do prywatności dokładamy TRIM (narzędzie zbudowane na bazie STRIDE). Jako biblioteka ataków pasuje OWASP Top 10, lista klas podatności na poziomie aplikacji.
A na czym? Naturalną notacją na tym poziomie jest DFD (diagram przepływu danych) albo PFD jak rysować DFD. I od razu zaznaczmy, bo to częste nieporozumienie: DFD to nie to samo co STRIDE. Jedno to sposób przedstawienia systemu (reprezentacja, czyli „na czym”), drugie to narzędzie, które popycha sesję do przodu (driver, czyli „czym”).
Artefakt? To model zagrożeń, ale już niekoniecznie tak formalny jak na poziomie systemu; często wystarczy DFD z listą zagrożeń, choćby w postaci zdjęcia tablicy z naklejonymi karteczkami. Jesteśmy tak blisko kodu, że najważniejsze jest co innego: od razu przekuwamy te zagrożenia w konkretne akcje w backlogu 5 formatów akcji do backloga. Model konsumuje zespół deweloperski, ale może też trafić do testerów QA (np. weryfikacja zgodna z ASVS) albo do pentesterów, żeby go zwalidować.
Tryb zaczyna się tu przechylać w stronę iteracyjną. Globalne modelowanie można jeszcze wcisnąć pod compliance, ale naturalnie pasuje już podejście iteracyjne. Kiedy? Przy zmianie w aplikacji albo pracy nad nowym feature’em, jako wydzielony wycinek sprintu, niekoniecznie dla każdej jednostki pracy.
Poziom 4: Funkcjonalność
Najniżej, najbliżej kodu. Modelujemy pojedynczą funkcję albo konkretne user story.
Kto? Tu już ewidentnie programista, Security Champion i tester QA lub tester bezpieczeństwa.
Czym modelujemy? Lekko i szybko: lekki STRIDE, abuse stories (historyjki z perspektywy atakującego), a do prywatności TRIM. Jako biblioteka ataków pasuje tu CWE Top 25, bardziej granularna niż OWASP Top 10 i przez to lepiej dopasowana do pojedynczej funkcji (OWASP Top 10 i CWE Top 25 są na innym poziomie logicznym). Sesje są krótkie, więc mogą być częste; można je sprowadzić do checklisty.
Artefakt? I tu rzecz kluczowa: na tym poziomie często nie potrzebujemy żadnego formalnego modelu zagrożeń. Możemy go mieć, ale zajmie nam to czas, a wartość będzie mała. Tym, co realnie wychodzi z takiej sesji, są kryteria akceptacji, wpisy do Definition of Done albo zadania w backlogu 5 formatów akcji do backloga. Praca jest tak blisko developmentu, że to, co znajdziemy, powinno dać się rozwiązać w obrębie jednego sprintu.
Tryb to czyste modelowanie iteracyjne, per sprint albo per story, wtedy kiedy uznamy, że warto. Można to robić zawsze albo tylko dla funkcjonalności o odpowiednio wysokiej krytyczności.
To wszystko jest gradientem, nie szufladkami
Wróćmy na chwilę do tego, co zaznaczyliśmy na początku, bo to ważne. Te cztery poziomy to gradient. Role, narzędzia i tryb przesuwają się płynnie z góry na dół: od globalnego modelowania przez bezpieczeństwo i architektów, aż po iteracyjne sesje programistów nad pojedynczą funkcją.
Granice są umowne. Security Champion w dużej organizacji bywa architektem i wtedy spokojnie pasuje wyżej, na poziom systemu. Pentester potrafi wnieść świetną wkładkę także na poziomie atomicznej funkcjonalności. Nie chodzi więc o zakazy, tylko o natywne dopasowanie: kogo realnie i z największym pożytkiem spotkasz na sesji danego poziomu.
Globalne czy iteracyjne? To też zależy od poziomu
Jeśli prześledzisz tabelę z góry na dół, zobaczysz jeszcze jeden gradient: tryb modelowania. Na poziomie organizacji i systemu sensowne jest modelowanie globalne (punktowe, kompletne, robione rzadziej). Na poziomie aplikacji zaczyna się mieszać: globalne i iteracyjne. A na poziomie funkcjonalności to już wyraźnie modelowanie iteracyjne, wpięte w rytm sprintów. Rozwijamy ten wątek osobno.
Wdrożenie: top-down czy bottom-up?
Skoro mamy poziomy, to pojawia się praktyczne pytanie: od którego zacząć wdrażać modelowanie zagrożeń w organizacji? Są dwie drogi.
Top-down oznacza start od góry, od poziomu globalnego (organizacja, systemy), a potem zawężanie procesu do mniejszych kawałków. Bottom-up to start od dołu, od pojedynczych funkcjonalności i podejścia iteracyjnego, i iście w górę. Co ciekawe, przy bottom-up możemy nigdy nie dojść do poziomu globalnego, bo okaże się, że organizacja jest na tyle mała, że go po prostu nie potrzebuje.
Pokażemy to na dwóch prawdziwych przykładach.
Pierwszy to BNP Paribas, duża instytucja finansowa, która potrzebowała obu torów naraz: globalnego modelowania dla systemów i organizacji oraz iteracyjnego dla aplikacji i funkcjonalności. Potrzebny był więc proces działający dwutorowo, obsługujący zarówno duży obraz, jak i mały wycinek. Wdrożenie szło top-down. Opowiadaliśmy o tym publicznie — na CSO Council 2024 oraz na The Hack Summit 2024 (wspólnie z Filipem).
Nie ukrywaliśmy zresztą, ile to kosztowało wysiłku: stąd tytuł obu wystąpień „O krętej drodze”. Jak padło ze sceny: „trochę nam to zajęło, nie ukrywam”. Wdrożenie procesu w organizacji tej skali to droga przez konkretne decyzje (PoC narzędzi, wybór modelu priorytetyzacji, notacja dla zespołów rozproszonych), a nie projekt na kwartał. I właśnie dlatego BNP podzieliło się tym publicznie: żeby kolejne zespoły nie szły tą drogą po omacku.
Drugi to jeden z naszych ostatnich klientów, gdzie założenie było odwrotne: to Security Championi i programiści mieli odpowiadać za modelowanie swojego wycinka. Bliżej tu do bottom-up i podejścia iteracyjnego. Co istotne, nie chodziło im wyłącznie o model „do pokazania” pod compliance, lecz o realne unikanie problemów bezpieczeństwa w swoich systemach.
Heurystyka, którą można z tego wyciągnąć: duża, regulowana organizacja z własnym działem bezpieczeństwa, IT i inżynierią zwykle potrzebuje obu torów i naturalnie idzie top-down. Mniejsza firma, bliższa technologii, częściej zaczyna bottom-up, i bywa, że poziom globalny nie jest jej w ogóle potrzebny.
Najczęstszy błąd: jedno narzędzie do wszystkiego
Wróćmy na koniec do tezy, bo teraz widać ją wyraźnie. Nie da się powiedzieć: „proces modelowania zagrożeń to DFD plus Microsoft Threat Modeling Tool i tyle”. Czemu? Bo programista na poziomie funkcjonalności, w środku sprintu, tego narzędzia nie użyje: na tym poziomie jest tragiczne. Na poziomie aplikacji czy systemu jest już znośne, może nie idealne, ale do przyjęcia. A na poziomie organizacji znów odpada.
To nie znaczy, że nie wolno niczego ujednolicać. Wręcz przeciwnie: warto ująć dobór narzędzi w procesie: „na tym poziomie używamy tego”, albo „tu masz kilka opcji, wybierz jedną”. Ale to coś zupełnie innego niż narzucenie jednego narzędzia wszędzie.
Co robić, jak żyć?
Zbierzmy to w pięć kroków:
- Ustal, na którym poziomie (lub poziomach) faktycznie modelujesz. Organizacja, system, aplikacja, funkcjonalność, albo kilka naraz.
- Dobierz rolę, narzędzie i artefakt do poziomu. Skorzystaj z tabeli wyżej jako ściągi.
- Zapisz to w procesie. Nie narzucaj jednego narzędzia dla całej firmy. Opisz, co pasuje na którym poziomie, i pozwól ludziom wybrać.
- Wybierz kierunek wdrożenia. Duża, regulowana organizacja: raczej top-down i oba tory. Mniejsza, bliska technologii: raczej bottom-up.
- Traktuj to jako gradient. Dobieraj odpowiednie narzędzie, nie szufladkuj na siłę, granice są płynne.
Bo modelowanie zagrożeń to proces, nie produkt. Jego sednem jest uniknięcie zagrożeń, które znajdziemy. Dobranie właściwego narzędzia do właściwej roboty to ta część, która długoterminowo decyduje, czy uda się ten proces wdrożyć i wyciągnąć z niego realną wartość.
Damy Ci znać, gdy opublikujemy coś nowego.
Artykuł albo odcinek podcastu. Bez spamu. W każdej chwili możesz się wypisać.
Zapisując się, akceptujesz politykę prywatności.
Referencje i wzmianki: Adam Shostack, Threat Modeling: Designing for Security; OWASP; MITRE ATT&CK; model C4 (c4model.com). O naszych wdrożeniach mówiliśmy też publicznie na CSO Council 2024 oraz The Hack Summit 2024.